沒想到第一篇技術分享文章會先從這個小主題開始。主要原因是之前在面試一家非常喜歡的公司,其中一個面試關卡因為沒有考慮到問題條件限制之一是 input 資料為以 base64 編譯後的資料,需要先用程式 decode 為 binary 再做後續處理,最後很可惜沒有進入下一關。後來回想一下,其實我在實習的時候就有碰過這個東西了,只不過當時做 base64 encode 我都直接把 service 密碼明文丟到 google 上的 “online base64 encoder” 直接做好 encode 後的 string🫠,算是根本沒懂過這個概念。所以決定針對他好好來研究一下,並記錄自己的研究內容~
base64 的基本概念
base64 是一種數據格式轉換方法,基本上 base64 encoding 的輸入資料會是一組二進制(binary)編碼,之後依照某種轉換規則,將一組組的 binary 數據對應到特定的 base64 character,最後再輸出一個 text form 的 output。
為什麼要做 base64 轉換?
主要原因大概如下:
-
提升安全性:
有時候一些人類很直觀能理解的密碼明文,比如 「
elaine_hsieh」,如果直接撰寫在 service configuration 上,會讓取得密碼的過程太過容易。如果將這樣的資訊包上一層 base64 encoding、變成「ZWxhaW5lX2hzaWVo」,之後有人想要取得 service 密碼將需要多一道解譯的手續。因此,透過 base64 encoding 可以進而提升一點資訊安全性。以 base64 編碼還有個額外好處:便於不同編碼方式之間進行數據轉換後的數據傳輸。
通常某個 service 密碼明文會使用 ASCII 或是 UTF-8 的編碼方式。使用 ASCII 的明文包含範圍較小,通常僅包含 256 個基本的字元,例如英文字母、數字、標點符號(此處指的是extended ASCII);使用 UTF-8 的明文包含範圍較大,例如英文字母、數字、標點符號、拉丁字母、中日韓等亞洲文字、表情符號與其他符號。由於 base64 character set包含了部分 ASCII character set,所以不論原始數據是以 ASCII做編碼(例:
titanin ASCII code)、或是以 UTF-8做編碼(例:titanin UTF-8 code),都可以透過 base64 轉換規則轉換為一組 base64 encoding(例:都會被 base64 轉譯為dGl0YW4=)。所以可以說,base64 可用於不同編碼方式之間進行數據轉換後的數據傳輸。如果要寬鬆一點說,base64 會有點類似於加密,只不過 base64 可以被輕易的反編碼、讀取到原文,並且此資訊公開給所有人,沒有公私鑰授權特定用戶的功能,所以嚴格來說 base64 不能算是一種加密 (encryption)方法,只能算是一種編譯(encoding)方法。
-
便於圖片、音樂、多媒體文件等資訊在網路世界中傳遞:
在 HTTP、SMTP 等網絡通訊協議中,想要傳送圖片等多媒體資訊其實會有很多限制。HTTP、SMTP、POP3、FTP 等網絡協議只能傳送 text form data,但是圖片、音樂、多媒體文件等資訊通常都會使用 binary code 來儲存資訊:比如像素、顏色深度、每幀畫面、音頻等,通常會用 16 或 32 bit 資訊做紀錄。
所以當我們想要用電子郵件傳送圖片時,我們會需要先將「
00101010101000001」的圖片 binary data,用 base64 轉換為「MDAxMDEwMTAxMDEwMDAwMDE=」,電子郵件的 html 形式會類似於 <img>MDAxMDEwMTAxMDEwMDAwMDE=</img>。之後傳送到目的方時,再使用 base64 decode 那串 text,就可以看得到<img> </img> 裡的內容了。
base64 轉換規則
以string input為例,大致上來說 base64 有四個步驟:
-
將 string 依照編碼(eg: ASCII) 轉換為 binary。我們知道 ASCII 編碼一共有 256 種可能,所以轉換後每個字母會對應到 0~255 ASCII number,與8 個bits。
-
將這些 binary 以每 6 bits 為單位進行分組。
-
將每組 bits 轉換為對應的 base64 character:
-
(1) base64 有一個自己的 character set, 只有 64 個 character,分別是:大小寫字母(A-Z、a-z)、數字(0-9)和兩個特殊字符(+ 和 /)。這也是 base64 得到這個名字的原因。
-
(2) 每組 binary 有6 bits, 相當於一共有 64 種可能性,正好可以對應到 base64 character set。
-
-
如果原始的 string長度不是3的倍數,base64 會自動補上一個 “="。
-
(1) 這麼做的理由相當於宣告最後一組bits「後面有補0,才得以是 6個bits」
-
(2) “=” 相當於宣告這組 bits的特殊性
-
-
最後將轉換後的 base64 characters回傳,即大功告成。
值得注意的是,base64 編碼後的數據通常比原始數據更長。這是因為 base64 編碼會將原本以 8 bits 為單位的 string,重新打散單位、轉換為 6 bits 的 base64 characters,這導致編碼後的數據會比原始數據增加約 33% 的大小。
舉例說明
假設我們有一串 string名為「Hello」,其長度=5,不是3的倍數。
-
依照 ASCII 編碼,「Hello」每一個 character 會對應到一個 8 bits 組合(=對應到 0~ 255 之間的一個數字)。組合起來即為「01001000 01100101 01101100 01101100 01101111」,一共 40 bits。
-
將以上 40 bits 每 6 個分一組,一共可以分成 6 組有完整 6 bits + 1組只有4 bits:「010010」、「000110」、「010101」、「101100」、「011011」、「000110」、「1111」
-
最後那一組補 0,讓他還是擁有 6 bits, 只不過後面放入一個 base64 character: “=",標註他的特殊性。所以就變成以下:「010010」、「000110」、「010101」、「101100」、「011011」、「000110」、「111100=」
-
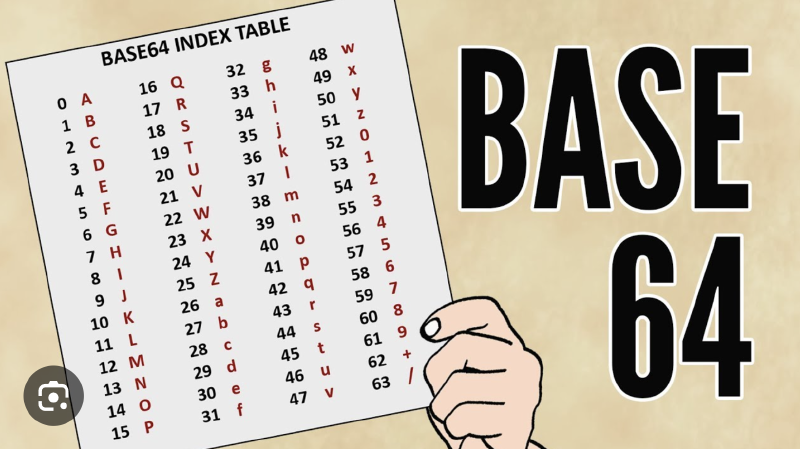
每一組對應到 base64 character set中的數字(對應表可以參考本篇文章的首頁圖)。
-
最後的 output即為 「SGVsbG8=」
python library 實作
在 python中,有很便利的 library協助我們做到 base64 encoding. 可以參考以下的 code:
|
|
結果如下:
|
|