
從二月準備正職面試以來,遇到了不只一家公司的面試需要考 system design,有鑒於自己在這方面的知識趨近於 0,剛好朋友分享一個開源社群每週三會定期舉辦一本 system design 書籍的讀書會,便想說藉此機會來讀這個領域有關的書,增加自己的知識量。
這次要讀的書叫做 <內行人才知道的系統設計面試指南 System Design Interview- An insider’s guide>,由 Alex Xu 撰寫,總共有 16 個 chapters,從一開始簡要的介紹 system 由小到大的擴展過程,一步步介紹系統內部元件,最後講解大型系統如 Youtube, Google 的設計思路。
在這一系列文章中,我會逐章整理每一個章節的內容、並分享一點自己的想法。
Chapter 1: 使用者人數 – 從零到百萬規模
這本書的第一章節是 <使用者人數 – 從零到百萬規模>,使用循序漸進的方法,帶我們了解系統是怎麼一步步擴大的,包含起點是什麼、怎麼疊加元件,進而長成一個可以承載高流量的系統。以下我把系統擴大的過程拆分為七個階段。
Phase 1: Init a system by Web server & DB server
想要打造一個系統,要從哪裡開始?最簡單也是最重要的就是先架一個 Web server。這個 Web server 會與 Web browser user 或是 App user進行互動。
接著,當使用者稍微開始增加後,我們想要將流量做簡單的分流管理,就會把 server 進一步拆成兩個server: (1) Web server, (2) Database server,如下圖。
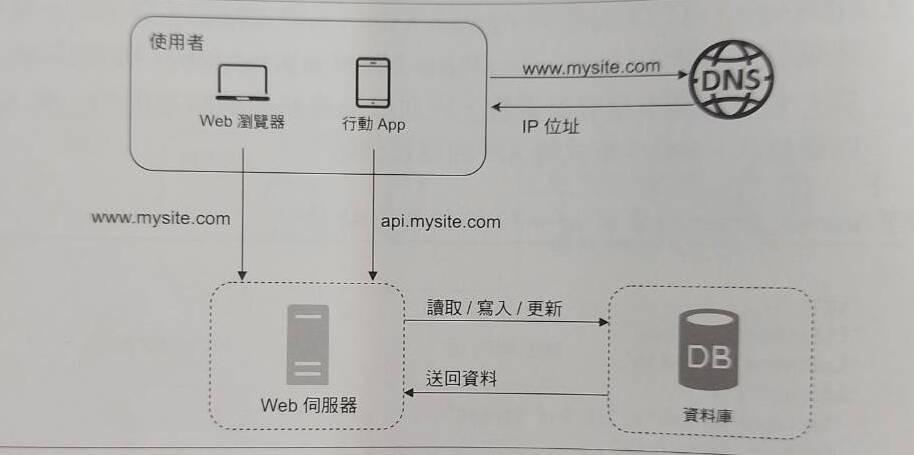
從此開始,我們以這兩種 server 為基礎,逐步擴大系統的元件。
Phase 2: Horizontal scaling
接著,當使用者再逐漸開始增加,我們想要擴展系統,該怎麼做?首先,我們要選擇一種高彈性、低局限性的擴展策略:水平擴展(Horizontal Scaling)。垂直擴展的意思是升級 server內元件規格,這種方法有硬體設計上的限制;水平擴展的則是指使用多台 server來平均分擔流量的方法。
在 Web server方面的水平擴展,我們可以使用增加多台server搭配負載平衡器(Load Balancer)的方法來達成目標,Load Balancer 會計算出最優的系統流量分配方法。而在 Database server上,我們可以透過使用資料庫複寫機制,意即使用一台 write-only master DB 搭配多台 read-only slave DB來達成目標。如果 master DB 掛了,會有其中一台 slave DB取代他。由於多數系統的 read 永遠大於 write,這麼做可以讓系統以平行的方式處理更多 query。
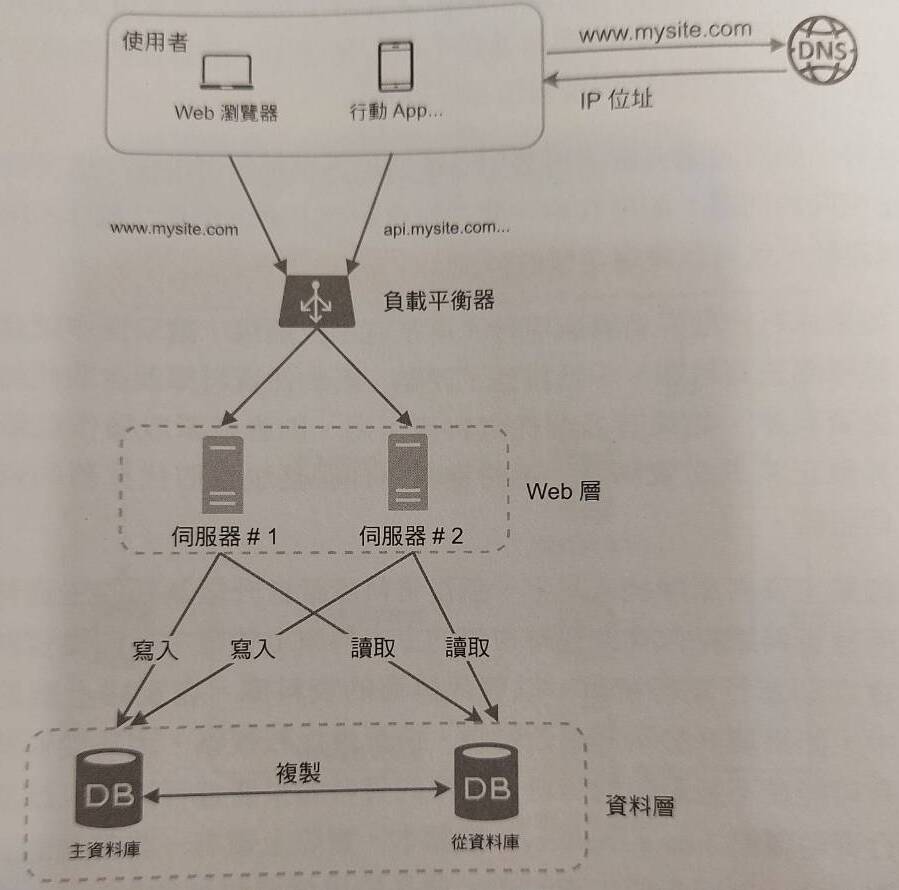
Horizontal scaling known as “Sharding”
書中有提到,水平擴展其實有個更廣為人知的名稱:Sharding(分片)。所謂的 Sharding, 意即做出許多個相同 schema 的資料庫,然後平均的把 data 透過 hashing 等方式分配給不同的 sharding DB。在 sharding DB 的使用架構中,最重要的是 hashing 方法中的 sharding key 是如何被選擇的?如果制定的不好,容易讓 data 通通集中於同一個 sharding DB,那就不好了。
書中提到了幾個有意思的 sharding 要考量到的議題:
- 如何制定具有一致性的 hashing method:
- 目的是讓 data 不會過度集中於一個 shard,或是解決當某個 shard 容量滿了之後如何重新搬動 data的問題。
- celebrity / hotspot problem:
- 某個 shard 因為太熱門,被過度的 read action 所淹沒。
- 可能的解決方法有:(1) 為每個 celebrity 制定一個 shard, (2) 每個 shard 可能要進一步 partition。
- 難以取得所有資料:
- 因為資料都放在不同的 sharding DB,難以做 json join。
- 可能的解決方法是將 schema 做 de-normalization。
Sharding vs Partition
這邊額外整理一個書中沒提到、但是常常看到的比較:sharding 跟 partition 的差異是什麼?簡而言之:
- sharding 是將 data 依據 hashing method 等方式分配儲存於不同的 databases, 分隔成實體的單位(實際意義上,這些資料位於不同地方)。
- partition 是將同一個 database 中的 data, 依據比如 country, department等單位再次做分割,分隔成虛擬的單位(實際意義上,這些資料位於同個地方,只是以邏輯意義分成不同組別)。
Phase 3: Cache & CDN
接著,當使用者再逐漸開始增加,service response time 開始變低,我們想要改善系統效能,該怎麼做?這時候我們以資料性質分成兩種處理方式:使用 cache 改善多數資料的存取速度、使用 CDN 改善靜態資料的存取速度。
Cache 是一個存取速度很快的臨時資料儲存層,介於 Web server 與 client 之間,根據不同的資料類型、存取模式等等,有許多種 request-cache-server 的互動方式(eg: read-through…)。要讓 Cache 既可以提升速度、又要維持正確性的方法,是仔細的思考 Cache system 的建構策略:什麼時候該使用 cache 而非query db、多久讓 cache中的資料過期、如何讓 cache 與 db資料保持同步、如果 cache 壞掉怎辦、cache 如果滿了怎辦…
CDN 是一個第三方供應商提供、為靜態內容提供快取的server,通常分散於地理位置各處。良好的、可以提升靜態內容存取速度的 CDN 很大關鍵取決於 user 與 CDN 之間的地理距離。如同 cache,要讓 CDN 可以良好正確的提升系統效能的方法是思考 CDN 的使用策略,包含過期時間設定、CDN壞掉時的備案措施。另外,CDN 使用成本也是建構系統需要考慮的一點,因此存放於 CDN 的資料必須是高使用率的。
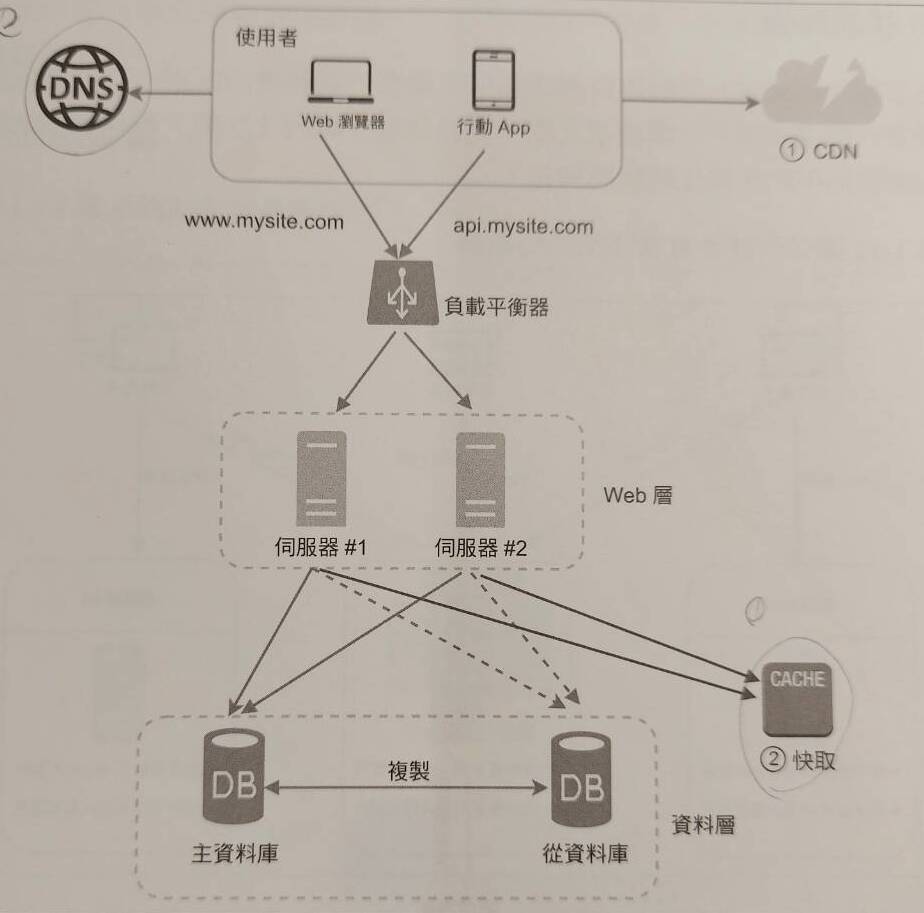
Phase 4: Stateless web server & Auto scaling
接著,當使用者再逐漸開始增加,我們想要進一步優化 service response time,該怎麼做?這時候我們針對 Web 層做進一步的優化,方法就是讓所有的 state 資料(eg: session)從儲存於 Web server 改成儲存於 DB server,使 Web server 成為 Stateless Web server。當 user request 發送到 Web server,相較於一台一台 server 去尋找該 user state data 的存放之處,在 Stateless web server structure 下,Web server 會統一尋找共用的 DB,取得該 user 的 state 資料。
另外,當變成 Stateless structure 後,就可以引入 auto scaling 機制,讓系統根據流量大小自動添加或移除 Web server。
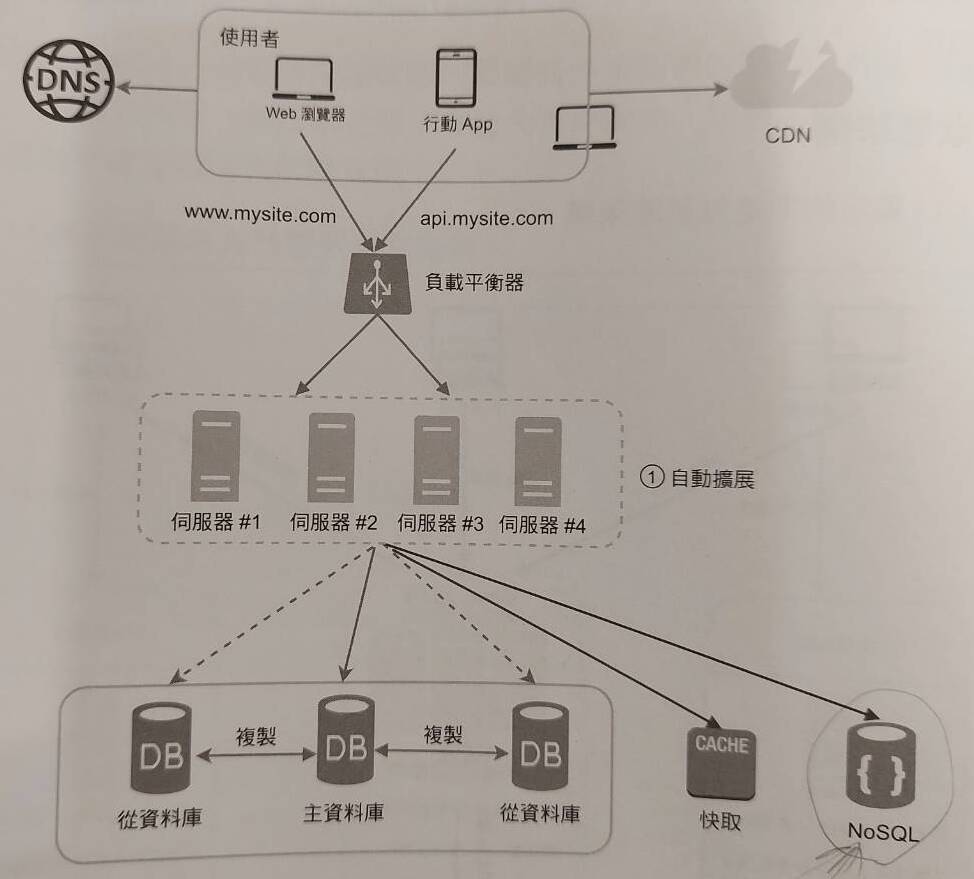
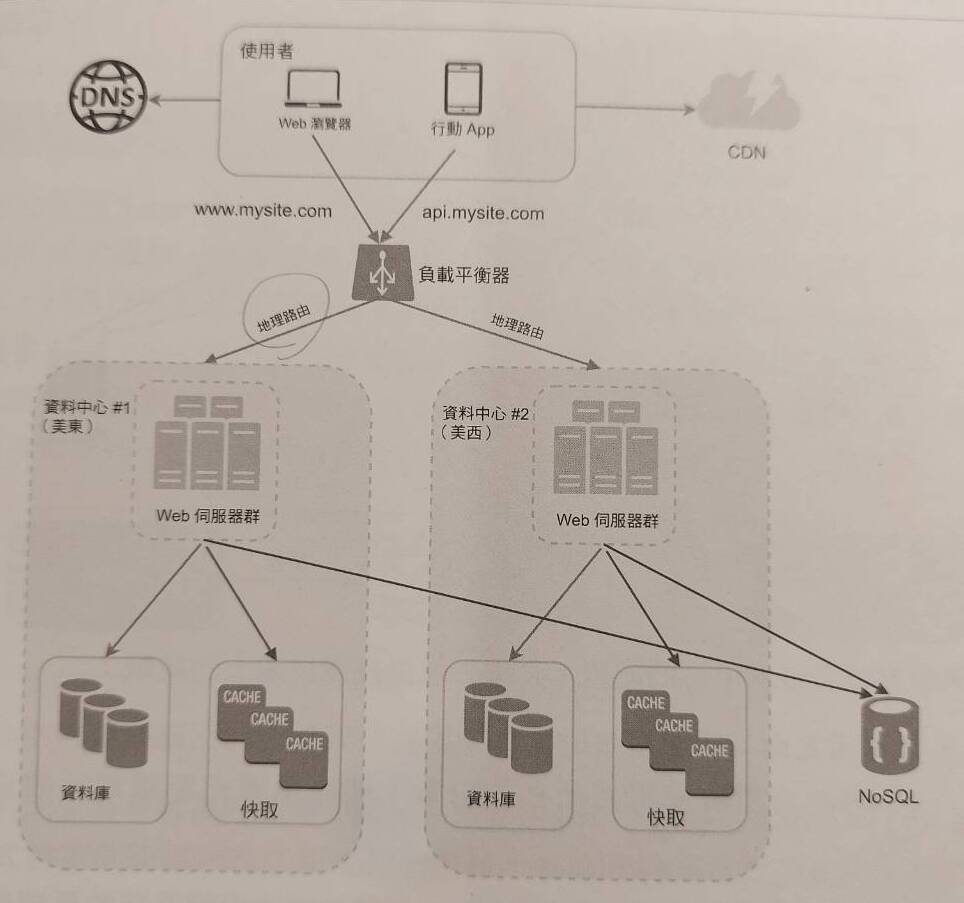
Phase 5: Data center
接著,當使用者再逐漸開始增加,開始有了國際化的使用者族群,我們想要進一步優化 service response time 與可用性,該怎麼做?
一個常見的方法,就是在不同的地理位置建構資料中心。user request 根據事先定義的流量分配比例,透過 geoDNS 被傳送到最近的資料中心的 servers。建構不同地理位置的資料中心也有其核心議題:
- 資料同步:通常不同地理位置的資料都會略有不同,如果一者故障、流量轉移至另一個資料中心時,該怎麼設計資料同步策略,才可以讓不同地區的 request 來到這處的資料中心也可以被 process。
- 服務一致性:要怎麼設計一套用於不同地區的測試、部署方法,讓不同地區都可以提供一致性或是相對應的服務?
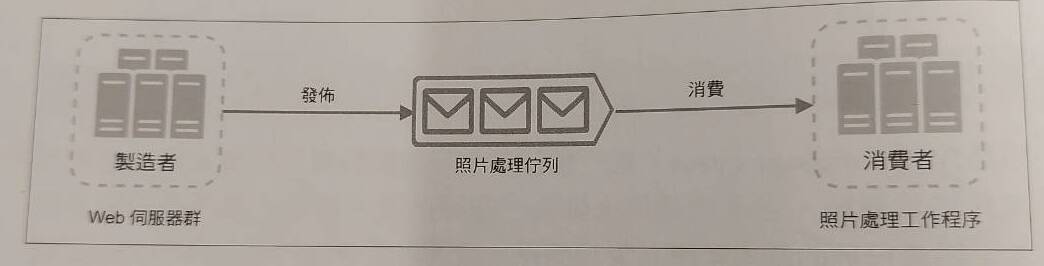
Phase 6: Message Queue
接著,當使用者再逐漸開始增加,而且我們的服務開始變得複雜:有些 services 需要很長的 process time。我們想要讓所有的 request 都可以順利被處理、同時優化 response time 與可用性,該怎麼做?
一個常見的的作法,是打造訊息佇列(Message Queue),來支援這種非同步的請求情狀,並把 Web server進一步拆分為 Web server 與 Worker server。
包含 Message Queue 的系統架構中,我們將發送 request 的 server 稱為 “Producer”,他會是一般的 Web server 。而接受 request 進行任務處理的 server 稱為 “Consumer”,他會是一個 Worker server。而 Message Queue 通常可以透過第三方服務 RabbitMQ 或是 AWS 的 SQS 來實現。
首先,Producer (eg: 接收 user request 的 Web server)會將一個複雜任務請求傳送到 Message Queue中。接著,Consumer (eg: 負責執行複雜任務的 Worker process/cronjob/service) 會從 queue 中提領出任務並解決。整個過程是非同步的,意即當 Producer暫時故障沒有發送 request,Consumer 還是可以繼續從 queue 提領任務;當 Consumer 還在處理上一份複雜工作未完成時,Producer也還是可以繼續接單,並傳送至 queue中。
Phase 7: Logging & Performance Metrics & Automation
最後,我們需要一個機制,讓系統內部發生的事情被紀錄,另外也需要一個元件來監控系統效能表現。透過設定 logging、建構 Performance metrics 並對其進行可視化,我們可以有效地掌握系統狀態並思考如何做得更好。另外,當系統越來越龐大,我們也需要制定 automation strategy (eg: cicd, testing),以提高生產力。
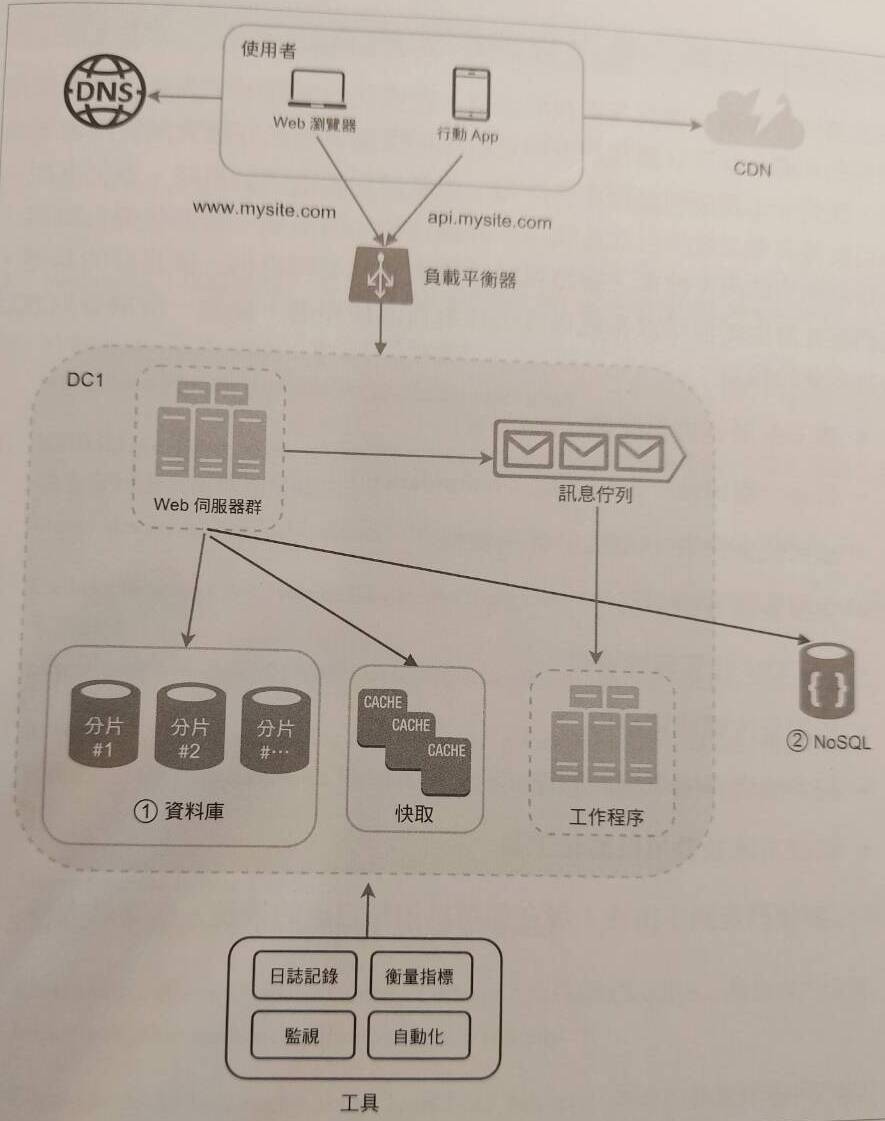
Conclusion
這章算是用很清楚且易懂的方式建構一個系統擴展的架構與思路出來,我覺得對我而言算是一個很好的思考基礎,之後再碰到關於系統設計從零開始設計的議題時,便可以開始想:web server 與 db server 可以分別怎麼擴展、遇到什麼樣的使用情境可以做什麼樣的優化。